Building Carbon Tech Is Simplifying Ground Operations in Disguise
Most conversations around carbon projects revolve around land eligibility, maps, biomass models, classification accuracy, and dashboards.
All of these matter but they are not where most carbon tech, especially digital MRV (DMRV) systems actually fail.
In practice, MRV breaks much earlier.
Before models. Before maps. Before dashboards.
It breaks at the level of operations and data.
Where DMRV Actually Breaks
When teams start building MRV systems, the instinct is predictable: automate workflows, integrate satellite pipelines, build dashboards, and scale models.
On paper, this looks like progress. On the ground, reality is far more complex.
MRV data doesn’t arrive neatly packaged. It comes from field surveys, multiple mobile data-collection apps, spreadsheets and CSVs, GPS devices, images, videos, and documents, and third-party service providers.
And each source brings its own problems—different schemas, inconsistent naming conventions, conflicting coordinate systems, and uneven levels of accuracy and completeness.
This is not primarily a tooling problem. It’s an operational problem.
The Automation Trap
One of the most common MRV failure modes is automating too early.
Automation is addictive:
- fewer manual steps
- faster processing
- the illusion of scalability
But automation doesn’t fix weak foundations. It amplifies them.
If your input data is inconsistent, automation simply scales the inconsistency, faster and more expensively.
In reality, this leads to pipelines that fail unpredictably, spatial joins that succeed technically but fail logically, dashboards no one fully trusts, reports that are painful to audit, endless clarification cycles with different teams.
Eventually, teams blame the tools, the GIS team, or edge cases.
The root cause is almost always the same:
The system was automated before the ground reality was understood.
Ground Reality Is Dynamic and Systems Must Be Designed for It
Field conditions are have their own challenges:
- Surveys happen in heat, rain, dust, and low connectivity
- Field teams have varying technical backgrounds
- GPS accuracy fluctuates
- Species names are local and inconsistent
- Time pressure encourages shortcuts
A strong MRV system does not assume ideal behavior. It is designed for these constraints, not despite them.
What Changes When MRV Is Treated as an Operations Problem ?

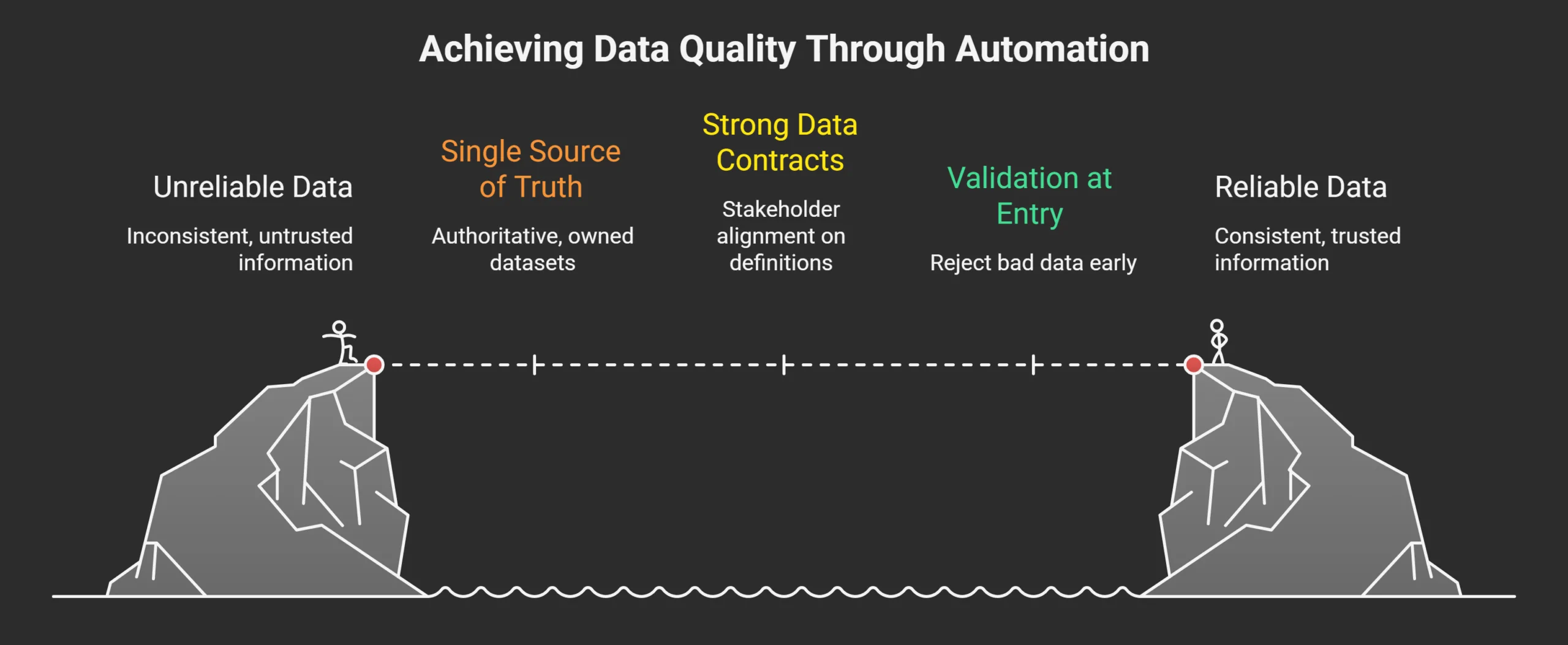
1. A Single Source of Truth (With Clear Ownership)
Authoritative datasets are explicitly defined and owned:
- Plots
- Surveys
- Maintenance and Monitoring
There is no ambiguity about “which data is correct” and no silent overwriting.
2. Strong Data Contracts
Before automation, stakeholders align on:
- schemas
- field definitions
- coordinate systems
- units
- naming conventions
This alignment is unglamorous but it prevents downstream chaos.
3. Validation at the Point of Entry
Bad data should be rejected early, not “fixed later”:
- coordinate bounds checks
- mandatory metadata
- unit and field validation
Upstream validation is always cheaper than downstream correction.
4. Transparent, Traceable Pipelines
Every transformation should be:
- explainable
- reproducible
- auditable
If a number appears in a report, the system must be able to answer:
Where did it come from?
How was it transformed?
Why should it be trusted?
If those questions can’t be answered clearly, the number doesn’t belong in the system
5. Automation as the Final Step
Automation should come after:
- Workflows are stable
- Ground constraints are understood
- Edge cases are documented
- Data quality is predictable
- Ownership and hierarchy are clear
The Shift MRV Teams Need to Make
Successful MRV systems aren’t built by asking: “How do we automate this faster?”
They are built by asking:
“Do we understand how this data is created, broken, interpreted, and trusted in the real world?”
Once that understanding exists, automation becomes straightforward, predictable and durable.
Final Thought
Carbon MRV doesn’t fail because teams lack expertise. It fails because systems are built on fragile operational foundations and automated too early.
If your MRV pipeline cannot clearly explain:
Where a number came from,
How it was transformed,
And why it can be trusted,
then it doesn’t matter how sophisticated the model is.
Till that point, it’s not a system!